H2モジュール仮説は、2026年のAI検索時代における戦略です(筆者提唱)。
この原稿では、H2モジュールという考え方は①この仮説が世界的な「アトミック・コンテンツ」理論と一致していること、②それを超える「インフォメーション・ゲイン」「セマンティック・チャンキング」「エージェント型SEO」という上位理論が存在すること、③具体的な実装方法の3点を解説します。
現在のSEOはある意味限界を迎えており、H2で区切る記事構成では不十分です。各モジュールに独自データを組み込み、AIに読み込ませる最適サイズで設計し、AIが信頼できる技術的証拠を提示して初めて、GoogleやChatGPTに引用される基盤が整います。
また2026年現在、検索エンジンは「リンク集」から「回答エンジン」へと大きな転換期を迎えています。
GoogleをはじめとするAI検索は、ユーザーの質問に直接答えを出し、そこに自社ブランドが引用されるかどうかで勝負が決まる……そういう世界線は、半年後には訪れるでしょう。
筆者はH2モジュール仮説は単なる文章構成の工夫ではなく、AIに情報を正しく読み取らせ、引用してもらうための必須条件だと考えています。詳しく見ていきましょう。

検索の大転換:リンクから回答へ

従来のSEOは、検索結果の青いリンクをクリックさせることが目標でした。しかし現在、Google GeminiやSearchGPT、Perplexityといったツールは、ユーザーの質問にその場で答えを生成します。ユーザーはもはやサイトを訪れる必要がありません。
この変化を「情報の非結合」と呼ぶ専門家もいます。
統計によれば、AI Overviewsが表示される検索では、通常の検索結果のクリック率が従来の1.41%から0.64%へと、実に55%以上も減少しています。つまり、検索結果に表示されても、訪問者は来ない時代が訪れているわけです。
ではSERP上のCTRの代わりに、何が重要になったのでしょうか。それは「AIの回答の中で引用される」こと。このあたりまでは、世界のSEO担当者の常識となりつつあります。
つまり、サイトへの誘導ではなく、情報源としての信頼を勝ち取ることが、新しい目標だというわけです。
| 比較項目 | 従来の検索(〜2024) | AI検索(2026〜) |
|---|---|---|
| 目標 | 検索順位の上昇 | AI回答での引用 |
| ユーザー行動 | リンクをクリック | 画面上で答えを得る |
| 評価単位 | ページ全体 | 独立した情報の断片 |
| 成功指標 | クリック数 | 引用される速度と頻度 |
この環境では、H2モジュール仮説の「各セクションの独立性」が重要になります。
AIはページ全体を読むのではなく、質問に最も関連する一節だけを抜き出して回答を作ります。そのため、各セクションが前後の文脈に頼らず、それだけで完全に意味が通じる必要がでてきました。
H2モジュール仮説:基本原理の確認
H2モジュール仮説とは、H2見出しを起点として、その下に書かれた内容を一つの独立したモジュール(部品)として構成する考え方です。各モジュールは以下の条件を満たします。
一つ目は、自己完結性。そのセクションだけを読んでも、何について書かれているか完全に理解できなければAIに引用されにくくなります。「それ」「この方法」といった曖昧な代名詞は避け、固有名詞や具体的な概念名を使う必要も出てきました。
二つ目は、回答ファースト構造です。H2見出しの直後に、その見出しが投げかける質問への答えを明示します。AIは各セクションの最初の40〜60語を優先的に抽出するため、この位置に核心を置くことが引用確率を高めます。
三つ目は、適切な長さです。一つのモジュールは150〜800語程度に収めます。これはAIの処理能力(コンテキスト・ウィンドウ)に合わせた設計であり、情報が途中で切れるリスクを防ぎます。
ただし、上記の要因(とくに三つ目)は、AIの進歩とともに大きく変化するだろうと思われます。
ただし、これを書いた直後から各AIのコンテキスト・ウィンドウは拡張され続けている点に注意してください。文字数の制約に関しては、差し引いて読む必要があります。
世界で語られる同じ理論=アトミック・コンテンツとモジュラー戦略

H2モジュール仮説は日本独自の発想……とも言いきれません。世界中のSEO専門家が、ほぼ同じ概念を「アトミック・コンテンツ」や「モジュラー・コンテンツ」として提唱しています。
アトミック・レジビリティ(原子レベルの可読性)
この理論では、記事のすべてのセクションが「原子」のように分割不可能な最小単位として機能すべきだとされます。AIがコンテンツの一部を切り取って使う際、その断片が単独で意味を成さなければ、AIは正確な情報抽出に失敗します。
具体例を挙げましょう。「この手法は効果的です」という文章では、「この手法」が何を指すのかわかりません。一方、「H2モジュール仮説は効果的です」と書けば、前後の文脈がなくても意味が通じます。こうした小さな配慮の積み重ねが、AI時代の文章品質を決定します。
モジュラー・コンテンツ戦略
ContentfulなどのCMS(コンテンツ管理システム)企業は、以前からモジュール型の記事管理を推奨してきました。記事を一つの固まりとして扱うのではなく、見出し、本文、画像、引用、行動喚起といった部品の集合として管理する方法です。
この方式には大きな利点があります。部品単位で更新できるため、全体を書き直す必要がありません。また、AIが必要な情報だけを取り出しやすくなります。ガートナーの調査では、売上高10億ドルの企業がこの戦略を導入すると、年間約400万ドルのコスト削減が見込めるとされています。
パッセージ検索
何年も前からGoogleがやるやると言いながら実現できなかったパッセージ検索も、AIの進歩とともに可能になりました。
パッセージ検索(Passage Retrieval / Passage Indexing)とは、Googleなどの検索エンジンが、ウェブページ全体だけでなく、そのページ内の「特定の段落(パッセージ)」を独立して評価し、検索結果に活用する技術のことです。
Googleは、彼らが「Hidden gem」と呼ぶ、これまでの検索システムでは拾えなかった無名だがすぐれた記事を拾うことが事実上できていませんでした。しかしこれからは、少なくとも記事全体ではなくパッセージ単位での評価が可能となります。
GoogleやOpenAIがHidden gemをすくい上げられるかどうかは難しいところですが、少なくともこれまでのGoogle検索よりもきめ細かな検査行動(AIによるものだが)が可能となるはずです。
上位理論①:インフォメーション・ゲイン(情報利得)
H2モジュール仮説を実践するだけでは不十分でしょう。さらに重要なのが「インフォメーション・ゲイン」という概念です。
これは、既存の情報に対して、あなたのコンテンツがどれだけ新しい価値を追加しているかを測る考え方です。Googleが2022年に取得した特許に基づいており、2026年のアルゴリズムの中核をなしています。
計算式を簡単に示すと、こうなります。
情報利得 = あなたの記事の情報量 − ユーザーが既に知っている情報量
どれほど高品質な記事でも、それが検索上位にある他の記事の焼き直しなら、情報利得はゼロです。AIはそれを「価値がない」と判断します。
情報利得を高める4つの要素
第一に、独自データの提供があげられます。自社で実施した調査結果、統計、売上データなど、他では得られない数字を示すことです。AIはこれを「唯一無二の事実」として重視します。
第二に、専門家の声。著名な専門家による独自のコメントや洞察を掲載します。これはE-E-A-T(経験、専門性、権威性、信頼性)の証明となり、AIの信頼性スコアを高めます。
第三に、独自の視点や反論があげられます。業界の常識に対して新しい解釈を提示したり、既存の理論に疑問を投げかけたりすることで、情報の多様性を生み出すことが評価につながります(※注)。
第四に、最新情報の速報性です。AIの学習データには時間的な限界があります。最新の出来事やトレンドを最速で報告することで、その遅れを補う情報源として採用されやすくなります。
逆に、絶対やってはいけないことはAI生成コンテンツをそのまま公開すること。AIは既存知識の平均を出力するため、それをそのまま使えば情報利得はゼロになります。人間の専門知識と実体験こそが、2026年における最大の競争優位性だ、といわれています。
注:ただし、独自理論が先進的すぎる場合、AIが既成概念と異なると判断して引用しなくなる可能性もある点に注意が必要です。
上位理論②:セマンティック・チャンキング(意味的チャンク化)
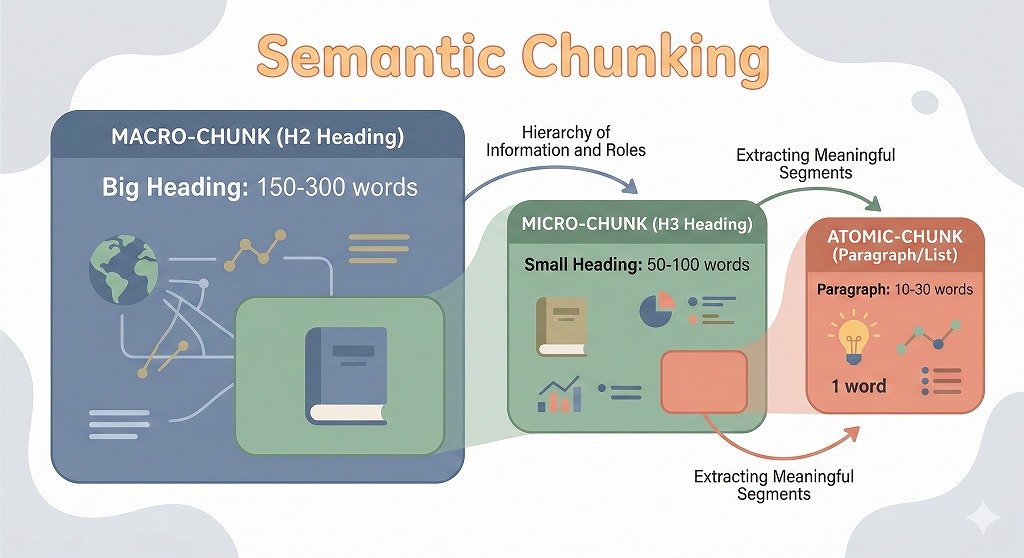
H2モジュール仮説が「見出し」という構造に注目するのに対し、セマンティック・チャンキングは情報のサイズと役割に着目します。
3つの階層構造
この理論では、コンテンツを以下の3層に分けます。
マクロ・チャンク(300〜800語)は、H2見出しで定義される主要セクションです。一つの大きなテーマや、ユーザーの主要な質問に答える単位となります。
ミクロ・チャンク(150〜250語)は、H3見出しで定義されるサブセクションです。具体的な手順、証拠、事例を詳しく説明します。
アトミック・チャンク(20〜50語)は最小単位です。箇条書き、定義文、重要な数値などがこれに当たります。AIが「回答の一部」としてそのまま使いやすい形式です。
現在の埋め込みモデル(GoogleのGemini EmbeddingやOpenAIのText Embedding)には処理容量の上限があります。各チャンクを150〜300語に保つことで、情報の欠落を防ぎ、検索クエリとの正確なマッチングを実現できます。
本稿制作時(2026年3月4日)からわずか2週間で状況がかわりつつあるため注意が必要。
10〜15%の重複ルール
高度なチャンキング理論には、興味深いポイントがあります。隣接するチャンク間に、10〜15%の「文脈的重複」を持たせるという考え方です。
完全に独立したモジュールを作りつつも、重要なキーワードや概念名をセクション間でわずかに繰り返すのです。これにより、AIが複数の断片を繋ぎ合わせて回答を生成する際、情報の連続性が保たれます。結果として、AIによる誤情報(ハルシネーション)のリスクが減り、引用の精度が向上する、とする仮説です。
ただし筆者はこの重複ルールには疑問を抱いており、さらなる検証が必要。
上位理論③:GEOとAEOの統合フレームワーク
H2モジュール仮説は、より大きな最適化戦略の一部として位置づけられます。それがGEO(生成エンジン最適化)とAEO(回答エンジン最適化)です。
GEO:生成エンジンへの適応
GEOは、大規模言語モデルの特性を深く理解し、AIが情報を「読み、理解し、使用する」すべてのプロセスを最適化する手法です。
エンティティの紐付けにより、コンテンツ内のキーワードを、Googleナレッジグラフなどの既知の「実体」として認識させます。たとえば「H2モジュール仮説」という固有名詞を、定義や関連概念と明確に結びつけるのです。
信頼のアンカーでは、業界賞の受賞歴、公的機関からの引用、専門家の署名といった第三者による検証を、AIが読み取れる形式で提供します。
信号密度の向上も重要です。従来のSEO記事よりも35%高い統計データの密度を目標とします。形容詞や比喩を減らし、検証可能な事実の割合を高めるのです。
AEO:ゼロクリック時代の戦術
AEOは、ユーザーがサイトを訪問しなくても、検索結果画面でブランドの信頼性を確立することを目指します。
従来のSEOが「人間の検索者」を対象としていたのに対し、AEOの主要オーディエンスは「AIエージェントと大規模言語モデル」です。成功の定義も、特定キーワードの順位から、引用頻度とエンティティの信頼度へと変化しました。
コンテンツの長さについても考え方が変わりました。従来はH2タグを1,500〜2,500語の網羅的な構成とする手法が一般的でしたが、現在は各セクション150〜300語の独立性が重視されます。
技術的焦点も、クローラビリティやサイト速度から、構造化データと情報の抽出可能性へと移行しています(※ただし筆者は現時点での構造化データ実装の効果には懐疑的)。
上位理論④:エージェント型SEOとコンテキスト・グラフ
さらに今後予測されるSEO理論では、検索者が人間から「自律型AIエージェント」へと移行することを想定します。これが「エージェント型SEO」です。
推論のシステム・オブ・レコード
エージェント型SEOでは、ウェブサイトは単なる文書の集まりではありません。AIエージェントが「推論」を行うための「知識グラフ」として機能します。
具体例で説明しましょう。ある製品を推奨するセクションを書く場合、単に「この製品がおすすめです」と述べるだけでは不十分です。なぜその製品が最適なのか、どのような基準で選んだのか、専門家の論理プロセスまで含めて公開します。
これをAIが処理可能な形式(MCP: Model Context Protocolなど)で提供することで、AIエージェントがその情報を「信頼できる推論の根拠」として採用する可能性が高まります。
SEO能力の4段階
専門家は、SEOの取り組みを以下の4レベルに分類しています。
レベル1(基礎的RAG)は、単純なテキストチャンクをベクトル検索可能にする段階です。H2モジュール仮説の基本形がこれに当たります。
レベル2(構造化知識グラフ)では、スキーママークアップとエンティティIDを用い、情報間の関係性を定義します。
レベル3(意思決定の透明性)では、専門家の推論プロセスをデータ化し、AIが論理を追跡できるようにします。
レベル4(エージェントの自律統合)では、AIエージェントがサイトの機能を直接APIで操作し、リアルタイムのデータに基づいてユーザーに代わってタスクを完結させます。
H2モジュール仮説は、レベル1からレベル2への移行を支える重要な基礎です。しかし真の競争力は、その上の階層である「推論の提供」にあります。
技術的実装:AIが信頼する基盤の構築

H2モジュール仮説を実効性のあるものにするには、HTML構造だけでは不十分です。とくに米国のSEO業界では、以下の技術的実装が必要だとされています。
セマンティックHTMLとセクション・コンテナ
各H2モジュールを<section>タグで囲み、固有のIDを付与します。これによりAIはページの目次を正確に理解し、特定のアンカー(#section-id)へ直接アクセスできます。
<article>、<header>、<nav>といったタグを適切に使い分けることも重要です。メインコンテンツとナビゲーション要素を明確に分離することで、AIの計算資源を本質的な情報抽出に集中させられます。
スキーママークアップによる証明
スキーママークアップは、装飾的なものではなく、AIに対する「一次キー」として機能するべきです。
FAQPageスキーマは、各H2セクションを質問と回答のペアとして定義し、RAGシステムが直接取り込める形式が望ましいでしょう。
PersonおよびOrganizationスキーマは、コンテンツの作成者が誰であり、なぜ信頼できるのかを証明します(もちろん完璧ではないが)。またSNSプロフィールやWikipedia、業界団体へのリンクを介して、「エンティティ」としての正当性を示すことを目指します。
Datasetスキーマは、独自調査の生データや統計情報をマークアップします。AIがその数値を「独自の事実」として認識し、引用する際の確信度を高めます。
最適化ツールとワークフロー
いうまでもありませんが、現代のSEOにおいては、人間向けの執筆と並行してAI向けの最適化を行う必要があります。
アトミック・エディタは、トークン制限内でのチャンク作成を支援します。スキーマ・ジェネレーターは、JSON-LDの自動生成とバリデーションを行い、技術的ミスによるエラーを防ぎます。MCPサーバーは、AIエージェント向けのリアルタイムデータを提供します。セマンティック・チェッカーは、エンティティ密度と信号対雑音比をリアルタイムで診断し、コンテンツの品質と独自性を客観的に評価します。
こういった技術により、H2モジュールは単なる見出し(チャンク)から、グローバルな知識ネットワーク上の「検証可能なノード(接点)」へと変貌します。
今後の展望:情報の完全性と非対称性の解消
H2モジュール仮説とその上位理論が目指すのは、情報のサイロ化を解体し、インターネット上のあらゆる価値ある知見を、AIを介して最短距離で、かつ正確にユーザーへ届けることです。
AIが検索の主役となる2026年以降、ウェブサイト所有者に求められるのは、情報の構造化と公開だと考えら得れます。情報の非対称性を利用した古いビジネスモデルは崩壊するでしょう。
自社の持つ知見を最も論理的に、最も信頼できるチャンクとして世界に提供できるブランドが、新しい時代の検索市場を支配すると考えられています。
まとめ:H2モジュール仮説とより高次元の仮説+実践
H2モジュール仮説は、世界的な潮流と軌を一にした、生成AI時代の検索戦略として妥当性の高い理論です。しかし単にコンテンツをH2で区切るだけでは、2026年の検索環境で勝ち抜くことはできません。
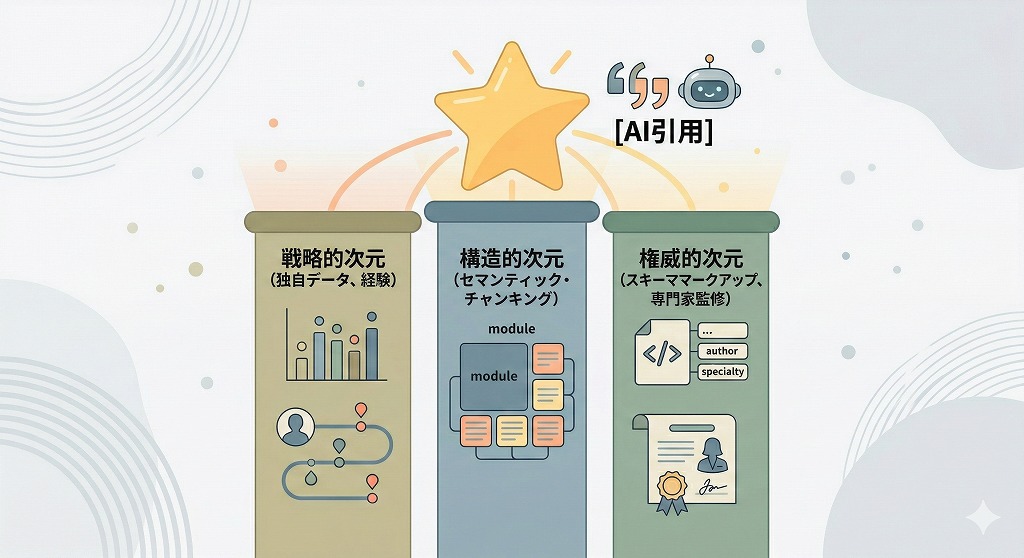
そこで、ウェブサイト運営者は、以下の3つの次元で戦略を拡張すべきです。
戦略的次元(インフォメーション・ゲイン)では、既存のコンセンサスをなぞるのではなく、自社にしか提供できない独自のデータ、洞察、経験をモジュールに盛りこみます。
構造的次元(セマンティック・チャンキング)では、AIのトークン処理能力に合わせ、150〜300語の範囲で自己完結した情報の塊を設計します。それらを論理的な重複によって繋ぎ合わせることで、情報の連続性を担保します。
権威的次元(エンティティ・コンフィデンス)では、スキーママークアップや専門家による監修を徹底し、AIが自信を持って引用できるだけのエビデンスを盛りこみます。
H2モジュール仮説は、ウェブライティングの終着点ではありません。AIと人間が共生する新しい知識共有の形を模索する方法論です。
この仮説を「回答エンジンへの適合」という文脈で捉え直し、常に「この一節はAIにとって、問いかけられた論点を説明するための最良のピースになり得ているか」を問い続ける姿勢が、2026年以降のデジタル・ビジビリティを決定づけます。